How do we do this on Hadoop data?


Source: https://cwiki.apache.org/confluence/display/Hive/Tutorial
Zohar Arad. © 2014
I am not a big-data scientist, but I am a big-data user.
Big data is a collective term for a set technologies designed for storage, querying and analysis of extremely large data sets, sources and volumes.
Big data technologies come in where traditional off-the-shelf databases, data warehousing systems and analysis tools fall short.
Data Generation: Human (Internal) ↦ Human (Social) ↦ Machine
Data Processing: Single Core ↦ Multi-Core ↦ Cluster / Cloud
Big Data technologies are based on the concept of clustering - Many computers working in sync to process chunks of our data.
Big data isn't just about data size, but also about data volume, diversity and inter-connectedness.
Any attribute of our data that challenges either technological capabilities or business needs, like:
Hadoop is a powerful platform for batch analysis of large volumes of both structured and unstructured data.
From: Conquering Hadoop with Haskell
Hadoop is a horizontally scalable, fault-tolerant, open-source file system and batch-analysis platform capable of processing large amounts of data.
HDFS is an ever-growing file system. We can store lots and lots of data on it for later use.
HDFS is used as the underlying platform for other technologies like Hadoop M/R, Apache Mahout or HBase.
Imagine we want to look at 30 days worth of access logs to identify site usage patterns at a volume of 30M log entries per day.
Hadoop M/R is a platform that allows us to query HDFS data in parallel for the purpose of batch (offline) data processing and analysis.
We demystified the term Big Data and glimpsed at Hadoop. Now What?
How do I really get into the Big Data world?
We collect data for the purpose of providing end-users with better experience in our business domain. This means we have to constantly query our data and divine new insights and relevant information.
The problem is doing that in very large scales is a painful, slow challenge.
Source: https://cwiki.apache.org/confluence/display/Hive/Tutorial
Hadoop gives us the basic tools for large data processing in the form of M/R.
However, Hadoop M/R is pretty annoying to work with directly as it lacks a lot of relevant tools
for the job (statistical analysis, machine learning etc.)
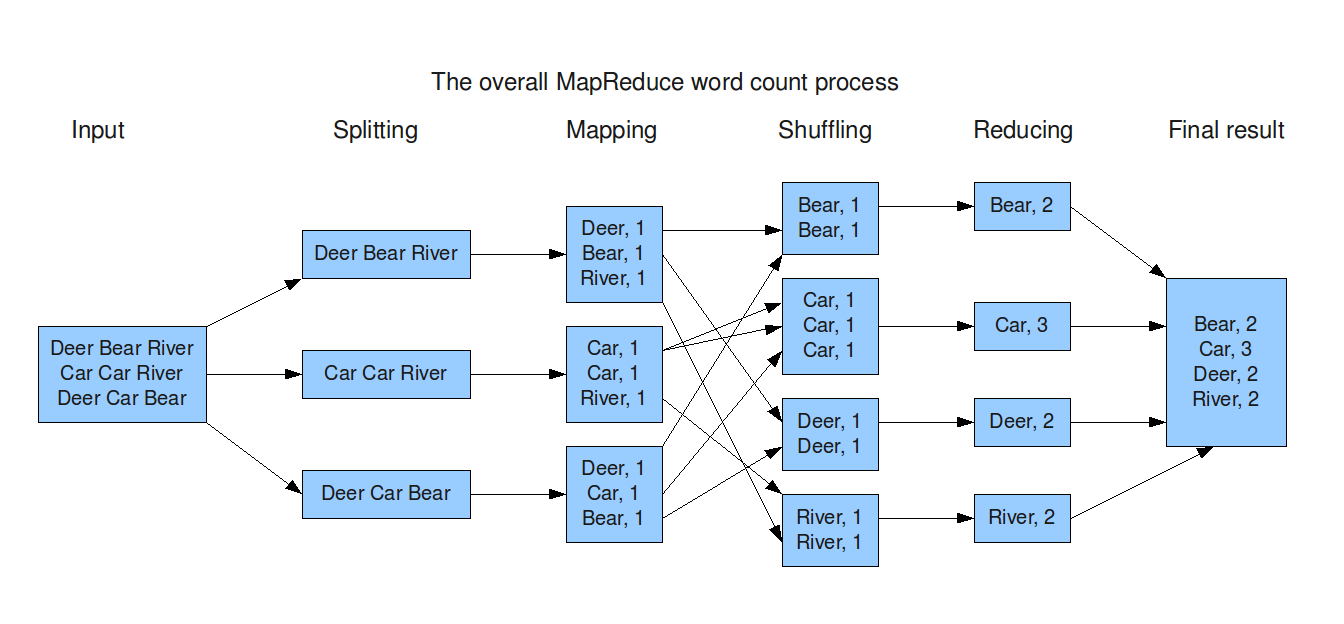
Source: http://xiaochongzhang.me/blog/?p=338
| Tool | Purpose |
|---|---|
| Hive | Write SQL-like M/R queries on top of Hadoop |
| Shark | Hive-compatible, distributed SQL query engine for Hadoop |
| Pig | Write scripted M/R queries on top of Hadoop |
| Impala | Real-time SQL-like queries of Hadoop |
| Mahout | Scalable machine-learning on top of Hadoop M/R |
The Problem: Traditional RDBMS were not designed for storing, indexing and querying growing amounts and volumes of data.
There's no single, simple solution to the 3S challenge. Instead, solutions focus on making an informed sacrifice in one area in order to gain in another area.
NoSQL is a term referring to a family of DBMS that attempt to resolve the 3S challenge by sacrificing one of three areas:
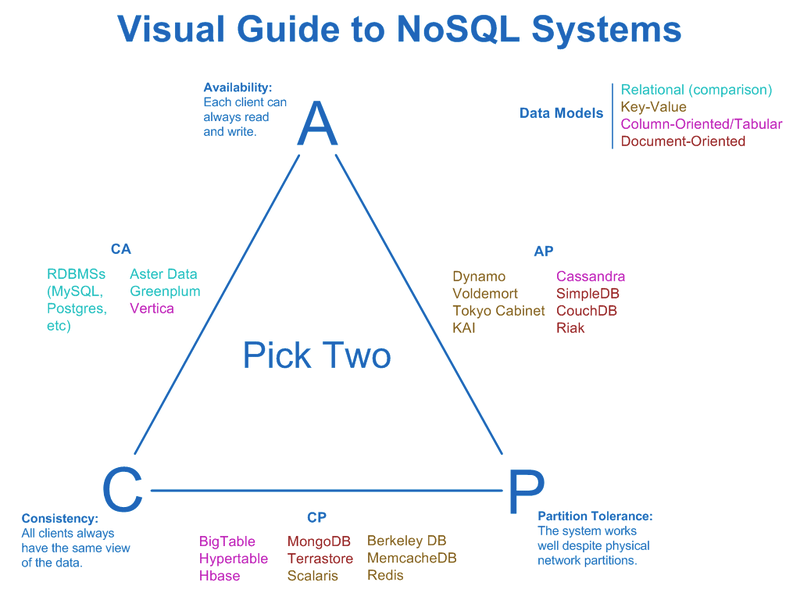
Source: http://blog.nahurst.com/visual-guide-to-nosql-systems
Processing big data in real-time is about data volumes rather than just size. For example, given a rate of 100K ops/sec, how do I do the following in real-time?:
When it comes to data processing and analysis, Hadoop's M/R framework is wonderful for batch (offline) processing.
However, processing, analysing and querying Hadoop data in real-time is quite difficult.
Apache Storm and Apache Spark are two frameworks for large-scale, distributed data processing in real-time.
One could say that both Storm and Spark are for real-time data processing what is Hadoop M/R for batch data processing.
| Term | Purpose |
|---|---|
| Big Data | Collective term for data-processing solutions at scale |
| Hadoop | Scalable file-system and batch processing platform |
| Batch Processing | Sifting and analysing data offline / in background |
| M/R | Parallel, batch data-processing algorithm |
| 3S Challenge | Size, Speed, Scale of DBs |
| C.A.P | Consistency, Availability, Partition Tolerance |
| NoSQL | Family of DBMS that grew due to the 3S Challenge |
| NewSQL | Family of DBMS that provide ACID at scale |
See presentation on http://goo.gl/NOq2qX
Feel free to drop my a line:
Email: zohar [AT] zohararad.com
Github: zohararad

Thank You!